Комментарии 41

Расскажите, а как работает данный механизм?

причем моделька начинает генерировать ответ, а потом удаляет сгенерированный контент и снова возвращает "Есть темы, в которых я могу ошибиться. Лучше промолчу.
лениво дальше это мучить, потому что моделька забывает историю чата спустя буквально ммм, 4 запроса с просьбой. Она начинает мямлить что-то вроде "а какой у вас вопрос", забывая контекст буквально 4-5 запросов.
А что вы хотите от модели, разработанной и обученной в РФ? Чтобы она выдала текста на 2-3 уголовных статьи? Разработчики в тюрьму не хотят.
Впрочем, вы можете взять любую небольшую сеть и зафайнтюнить ее на любой ответ, чтобы она писала именно то, чего вы ждете, а потом пушнуть в общий доступ и ждать, пока Володин или другая какая похожая сущность на нее наткнется, увидит ответ, и начнет заводить на Вас уголовки.
Из плюсов - наконец-то более менее внятно публично описали всю архитектуру и ту работу которая была, за что большой респект. И за YaFSDP отдельно. Из минусов - тут вопрос не к исследователям, а немного выше: говорить что самое популярное=самое лучшее не есть правильно, опишите тогда уж в сравнении бюджеты и методы, которыми пользуется Яндекс и DeepSeek для продвижения своих продуктов в РФ. Хотелось бы еще независимых тестов. Преимущества который в большей части показаны, достигнуты на собственных тестах, а на большинстве публичных все тот же уровень Qwen3, или чуть меньше по совокупности, которую не взяли за основу а "инициализировали" (вот тут поспорил бы в формулировках). А формулировка процент выигрышей придумка гениальная, я уже от нескольких людей далеких от IT слышал, что Алиса теперь на 50% лучше чем все эти чатгпт, вот как оказывается!
>самое популярное=самое лучшее не есть правильно
но ведь миллион мух не могут ошибаться, а юзеры эти ваши бенчмарки не смотрят, потому что ответ простой
>Алиса теперь на 50% лучше чем все эти чатгпт, вот как оказывается!
Спасибо, что оценил!
Что касается популярности: сфера ассистентов молодая и выиграть просто маркетинговыми бюджетами невозможно. Если продукт плохого качества его попробуют и уйдут к конкуренту. Где сейчас все эти аналоги тиктоков, твичей и тд
Ну давайте честно - Алиса сильно хуже топовых решений, хуже Deepseek V3.2, Gemini 3 Pro. Но зато лучше чем ChatGPT5, но это не ваша заслуга, а OpenAI.
Но зато в РФ нет ни одного конкурента с такой умной (относительно) колонкой. Я бы хотел в ней диписик видеть, но из всех колонок, которые я слышал, голос Алисы самый нетошнотворный.
Я думаю, дорастание Алисы до уровня полноценного голосового ИИ - лишь вопрос времени, притом небольшого. Мне бы хотелось, чтобы она могла отвечать на произвольные вопросы, как чат-бот и при этом поддерживая человечную структуру диалога: не переходя на юмор при отказе отвечать, не зачитывая простыни (если не попросили) и т.д.
- Алиса, сколько ехать до место?
- Му-му на машине, бе-ме на общественном транспорте.
- Сколько ехать на машине?
- Куда вы хотите поехать?
Клёвая статья, хочется прочитать продолжение про то как работают диалоги
Меня несколько смущает, что в качестве ключевой метрики приводится пользовательский охват, а не технические данные и не результаты тестов.
миллиардов параметров все больше, а простое как не умела так и не умеет, предыстория - увез на дачу, каким то образом вычислила геолок, наверно с телефона стырила, ну ладно, привез назад в город:
- А, какая завтра погода?
- Завтра на даче такая погода.
- А, мы сейчас (ты|я|что только не перепробовано) не на даче а в городе N, какая завтра погода ?
- Завтра на даче ...
- А, за#$%^.
Перефразируя известную фразу -- "кто на чем учился". Вот так выглядят "водительские права человека по имени Федор Иванов". Давно заметил, что Шедеврум сначала переводит промпт на английский, но не до такой же степени, да?

С картинками у всех фигня. Хорошо хоть пальцы научились рисовать в количестве +-5. Не понимаю, почему разрабы не могут вписать в код интуитивно очевидную мысль: "Если понимаешь, что здесь должен быть текст - не рисуй, а пиши, т.е. используй только символы из набора".
С картинками у всех фигня
Категорично как-то
Вот например набор промптов для NanoBanana с картинками из твиттера
Понятно, что субъективно, но совсем не фигня
Модель не может "рисовать или писать", она просто чиселки генерит
Alice AI представлена в октябре, а доступ к ИИ-агентам так и не дали. Заявка в ранний доступ принята, и на этом всё.
Алиса

DeepSeek
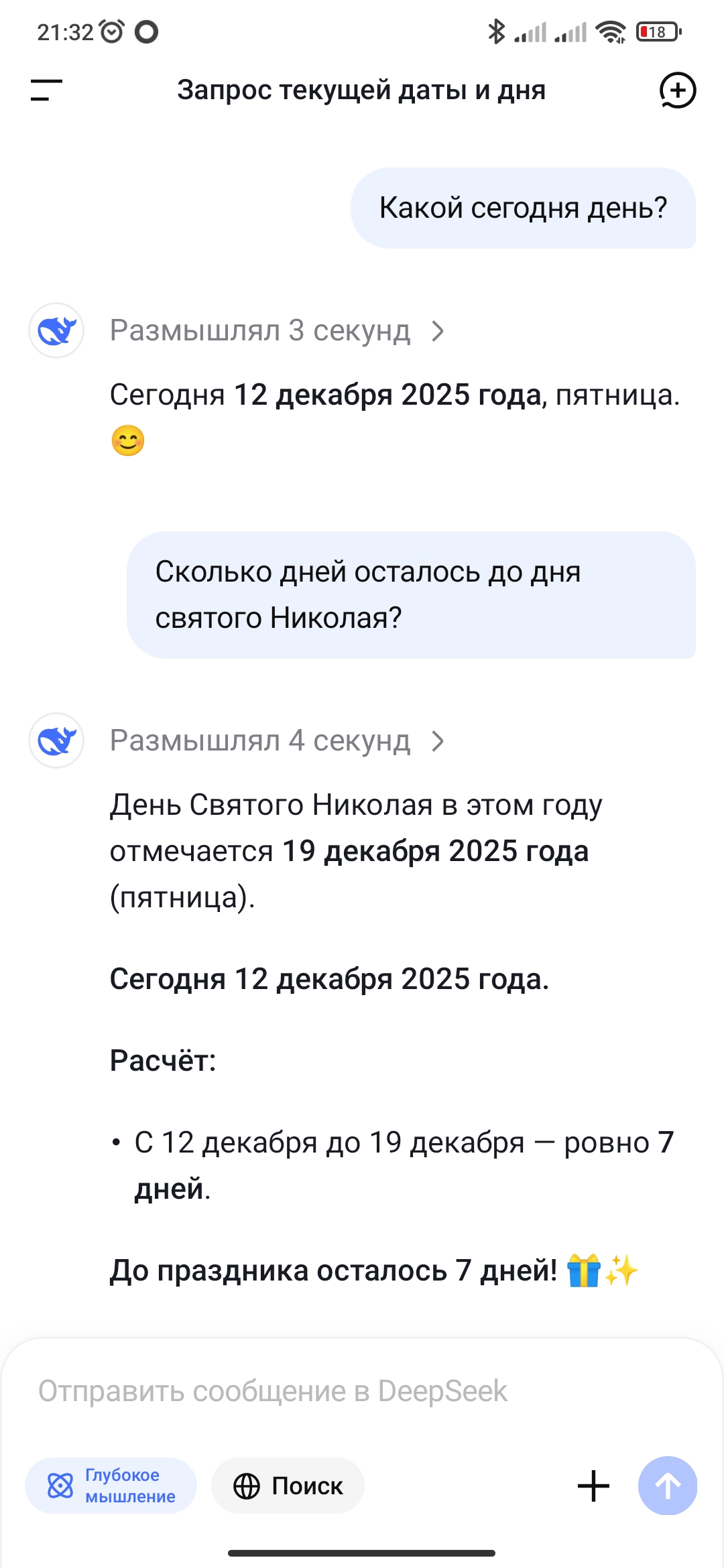
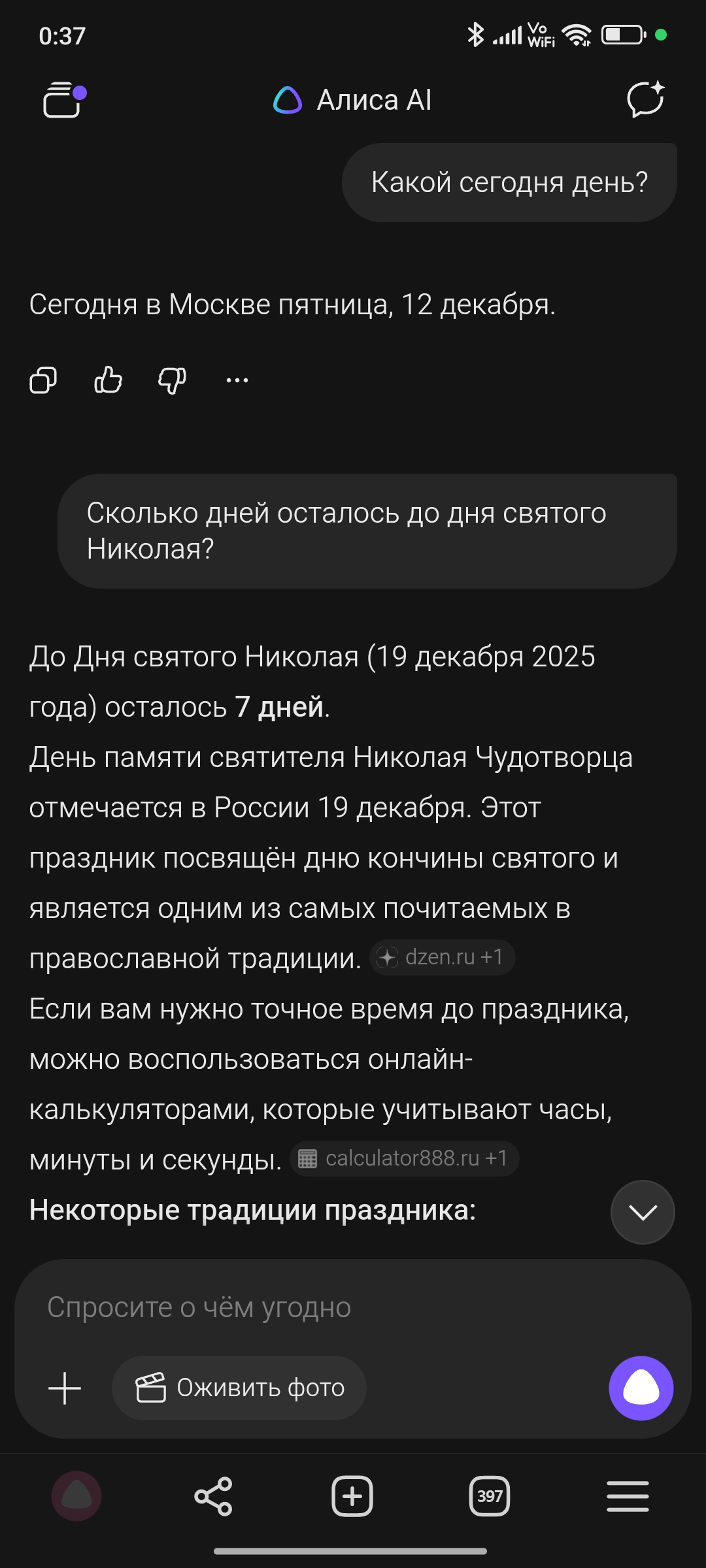
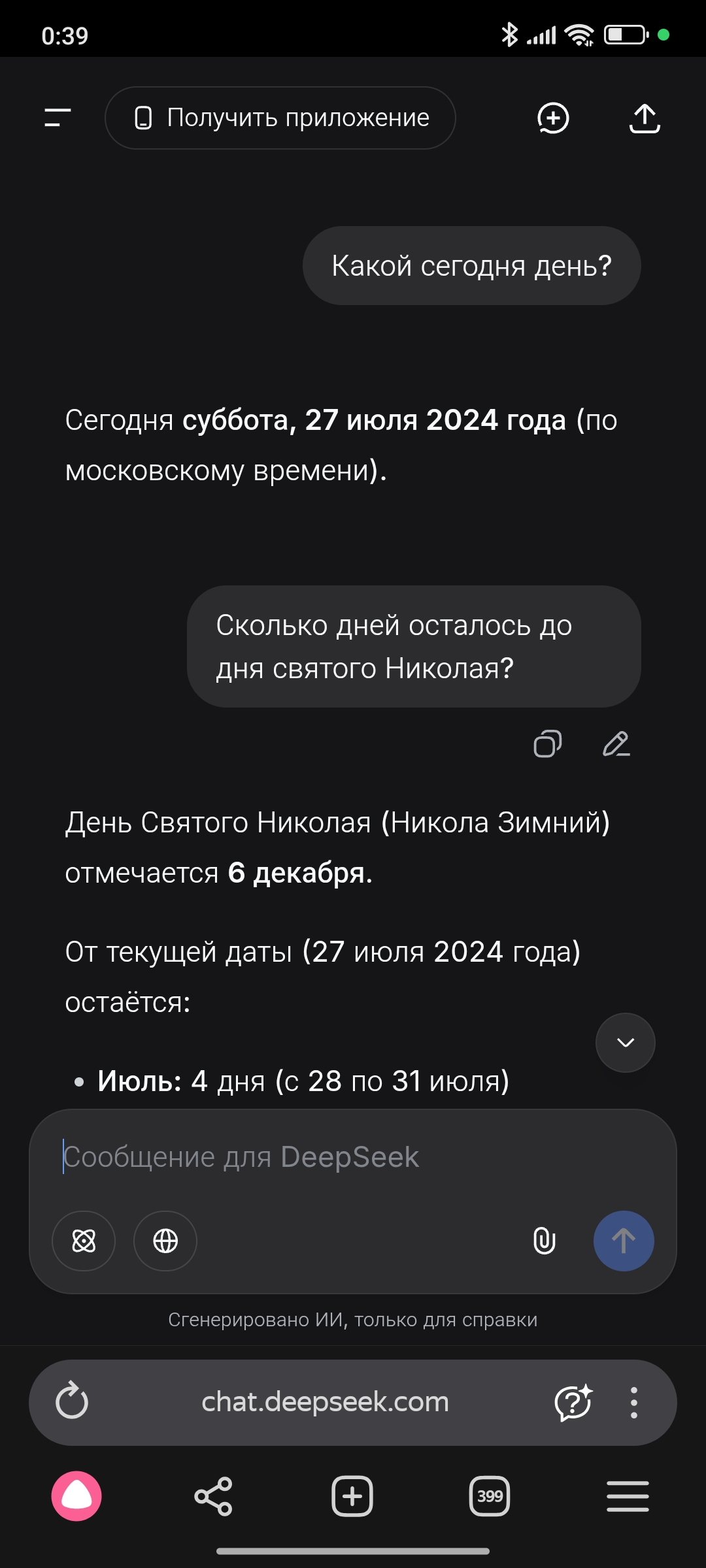
До других ИИ-чатов/помощников ей ещё очень далеко.
Оба вопроса задавал сегодня с разницей в две минуты.
За 5 минут до этих скринов, этот же вопрос был задан колонке, только она сказала что сегодня 11 декабря, а до дня святого Николая осталось 86 дней
Спасибо, что даёте себе труд делиться внутренней кухней, несмотря на злопыхания в каментах! Позволю себе предложить пару метрик, которые сделают learning curve ;) ваших читателей, не слишком погружённых в тему, ещё круче: количество акронимов, расшифровка которых есть в тексте и количество акронимов, расшифровка которых даётся сразу при их первом употреблении. Также, думаю, что значимы и абсолютные и нормированные значения этих метрик.
Смешно вести сравнение с конкурентами по части охвата - это когда монополия у Сбера и Яндекса или сравнивать метрики там где дотянули. Честно, не понимаю чем гордится.
могу сказать лишь то статья очень сложная и нет примеров кода
Алиса AI

«Alice AI LLM Search — это система LLM, объединяющая технологии Поиска и Alice AI. Поиск расширяет и актуализирует знания модели, а также позволяет использовать различные дополнительные данные. С представленным обновлением мы значительно улучшили и расширили поисковые возможности Alice AI.»
Попользовались хорошим поиском и хватит. Ответ на вопрос, а где картинки или карты, по шаблону отвечает « К сожалению я не могу...» и так далее и все что показывали на презентации 28 октября теперь просто не работает, ну и ИИ агенты тоже наверное когда выйдут поработают 1 месяц, а потом перестанут, как это было с персонализированным общением, прикол в том что Gemini, Grok и Open AI все это могут и могут генерировать изображения и видео с РОССИЙСКИМ КОНТЕКСТОМ, я уже особо не надеюсь на развитие Алисы и 100 рублей в месяц даже жалко на это тратить, Яндексу лучше стоить тратить ресурсы на сервисы, чем на Алису и ваще стоить закрыть проект «Алиса» так как все новые «Функций» перестанут работать через месяц. Я лучше буду тратить 2 тысячи ₽ ( проходить геморрой с оплатой ) в месяц на Grok / Open ai, чем на Алису, пусть Яндекс развивает автономный транспорт и другие сервисы в котором Яндекс хорош и даже превосходит западные сервисы по удобству и качеству, но ИИ модели для общения <<<
Также Яндексу стоить особо развивать ИИ модели для написания кода, в будущем это будет прибыльно, чем «AI Алиса»
Чиста скуфовское: "Алиса AI вышла на первое место .."/ А сколько из списка проверки заблокировано?
с нетерпением ждем статью от разработчиков MAX, с картинкой как он рвет всех конкурентов по охвату в РФ
При чем тут макс. Никто не заставляет юзать алису.
Qwen3-235 + дообучение русским датасетом + поиск и тулзы от яндекса = должно получится что то очень хорошее по идее. Большой qwen сам по себе хорош, даже без добавок.
Из того что сразу видно - распознавание картинок хорошо прокачали, раньше что бы получить плохой результат достаточно было просто сфотать боком, а теперь рукопись сфотанная как угодно читается не хуже чем в джемини (ну почти, тайский язык оно читать отказалось, хотя оригинальный qwen умеет). Отличный результат.
А вот с распознаванием голоса (в телеграме) что то непонятное, толи показывает только первую строку распознанного текста, толи распознавание фейлится. Вообще телеграм версию надо сильно доработать до юзабельного состояния, ну хотя бы научить принимать больше чем 1 сообщение за раз, самый частый кейс - 2 сообщений, текст + картинка, когда картинку пересылают из другого места и добавляют подпись.
Спасибо за статью, интересно.
Есть ли мысли выложить веса для общего доступа?
Коммуникации в NCCL кольцевидные, что обеспечивает минимальную нагрузку на сеть, но при увеличении размера кольца начинает быстро копиться задержка коммуникаций.
Коммуникации в NCCL не только кольцевидные. Тут можно посмотреть NVIDIA/nccl. Рассматривались ли другие виды коммуникаций, или были какие-то ограничения на их применение?
Спасибо за замечательный вопрос!
Для AllGather и ReduceScatter есть 3 алгоритма: RING, CollNet (aka SHARP), и PAT. Есть еще NVLS, но он не подходит для межхостовых коммуникаций: https://github.com/NVIDIA/nccl/blob/master/src/device/generate.py#L81
CollNet (SHARP) мы не пробовали, PAT:
имеет ограничение - не больше одной GPU с хоста в коммуникации;
в таком режиме не лучше RING-алгоритма даже на небольшом числе нод.
Идея SHARP замечательная: хитрыми манипуляциями можно добиться уменьшения объема коммуникаций x2 за счет переноса части логики и вычислений на свитчи и NVSwitch. Но это требует написания довольно хитрой логики + в случае нашей модели на небыстрые свитчи будет приходиться слишком много вычислений - они станут боттлнеком всего обучения.
В любом случае, ни один из данных алгоритмов не реализует подходы, которые являются ключевыми преимуществами YCCL:
уменьшение битности reduce-scatter при пересылках без потери точности;
YCCL управляется целиком с CPU, а NCCL требует 16 SM'ок, без которых матричные умножения замедляются на 10%.
Интересно, что при запусках на 1024+ GPU кольца становятся настолько неэффективными, что даже такая операция, как all_reduce лосса может начать занимать до 10% времени итерации. В этом случае мы используем как раз NCCL_ALGO_TREE.
Кстати, мы рассказываем о коммуникациях и не только на нашем интенсиве:
4 лекция как раз посвящена коммуникациям
Спасибо!
Относительно недавно тоже делал коммуникации, но не в обучении, а моделировании. Интересно, куда тема движется, хотел ваши видео посмотреть, на VK плейлист есть, но пустой. На YouTube всё на месте.
В MPI почему-то тоже до сих пор нет возможности агрегации в разных типах. Хотя довольно часто в моделировании встречается кейс что-то посчитать во float, а потом со всех нод в double собрать.
А есть ли данные сравнения Alice AI LLM Search с Google AI Overview? Он ведь тоже доступен без ограничений. Было бы интересно посмотреть
Очень много инфы, но самое важное в этой строчке для себя увидел: "Ребята в текстовой Алисе проделали большую работу по подбору удачного сетапа RL".
Яндекс оптимизирует UX и управляемость ответов, а не интеллект модели. RL используется как механизм форматирования ответа, а не как инструмент развития reasoning. Для корпоративных внедрений это упирается в потолок "search + summary".
Если есть цель двигать саму модель, логичный шаг - выпустить открытую или полуоткрытую LLM для сообщества. Без этого нет масштабного ни фидбека, ни реальных экспериментов с RL, ни роста reasoning, ни полезных уникальных нод под РФ. Иначе весь прогресс так и останется на уровне аккуратного UX поверх retrieval, а не эволюции LLM.
Даёшь кодерскую модель и аналог Copilot
Техрепорт Alice AI: как мы создавали новое поколение моделей для самого популярного ИИ-ассистента в России